
本記事は、AIエージェント・ストラテジスト試験(AICX協会主催)の公式シラバスver1.0 Chapter 3 / Section 16「AIエージェントが読みやすいデータを作る」 の解説です。RAGやナレッジベースの精度は、結局のところ 元のデータがAIにとって読める形かどうか で決まります。
到達目標は、AIエージェントにとって扱いやすい/扱いにくいデータの特徴、データ品質を高める実務の工夫、AI Readyデータの考え方、既存データをどこまで整形すべきかの判断を理解すること。
人の読みやすさ ≠ AIの読みやすさ
セルを結合して中央揃えにした表は、人が見るぶんには整然としていますが、AIが読むと 行と列の対応が崩れ、どの値がどの項目か判定できません。議事録に「例の件、確認済み。OKとのこと」とだけあっても、AIには「例の件」が何か分かりません。こうした曖昧な記述が、「ナレッジベースに入れているのにRAGの精度が上がらない」原因になります。
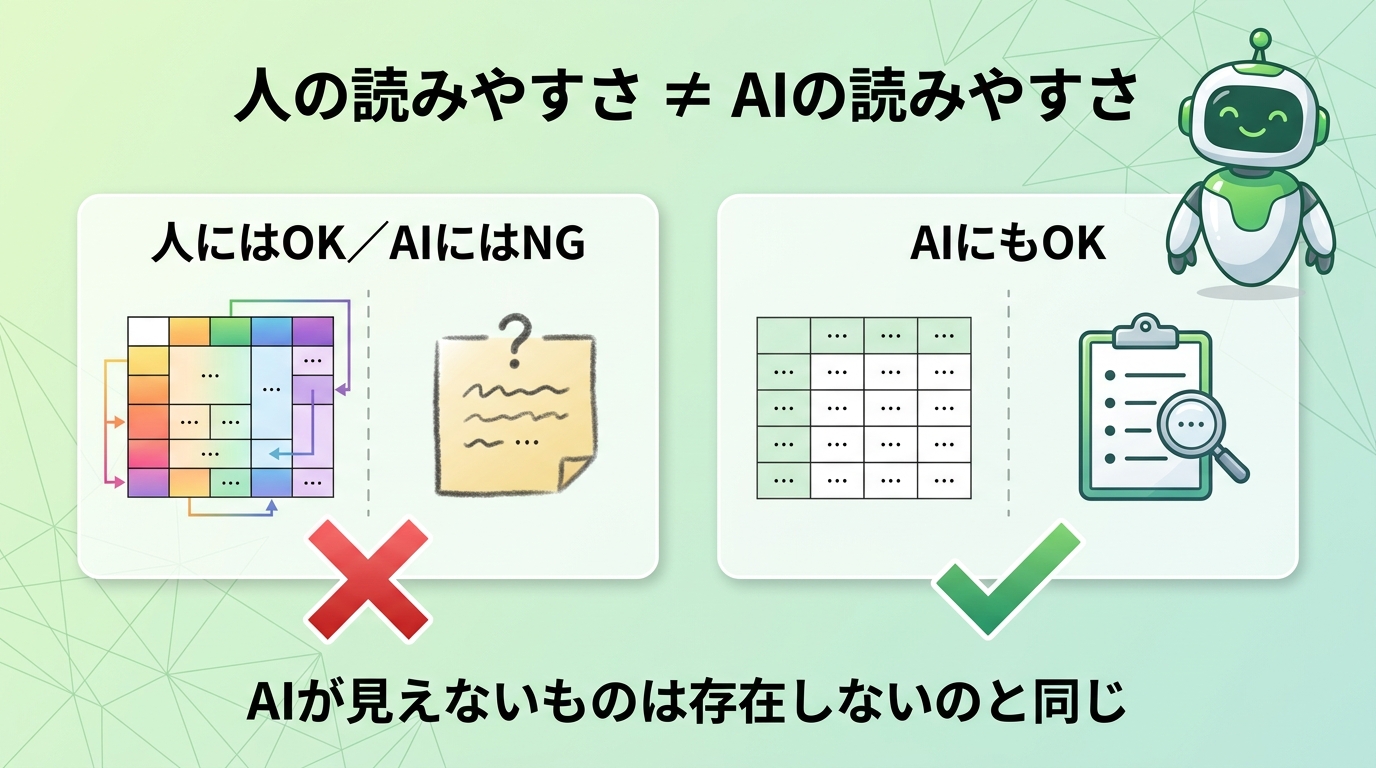
AIが扱いやすいデータの条件は、①記述だけで意味が分かる ②1つの項目に1つの情報だけ ③情報の構造が文字として明示されていること。押さえるべき原則は 「AIが見えないものは、存在しないのと同じ」。どれだけ価値がある情報でも、テキストとして明文化されていなければAIは活用できません。
今日からできる7つの習慣
いずれも業務を大きく変えず、日々の進め方を少し見直すだけで実践できます(「AIのために新しい作業を増やす」と受け取られると定着しません)。
| # | 習慣 | ポイント |
|---|---|---|
| 1 | 固有名詞で書く | 「例の件」→「2026年3月のサーバー障害対応と同じ手順で」。察してもらう表現はAIには存在しない情報と同義 |
| 2 | 「見た目」より「構造」 | セル結合しない・色で意味を持たせない・1セル1データ。基準は「フィルタ/ピボットが使える状態」 |
| 3 | 正しい入力がラクにできる環境 | 表記ゆれ(トヨタ/Toyota)を防ぐ。プルダウン・マスタ参照で仕組みで品質を担保(人の注意力に頼らない) |
| 4 | 重要な画像に注釈 | スクショや点検写真に「右上の配管に亀裂あり」とテキスト注記。画像内文字はそのままでは読めない |
| 5 | 日付とカテゴリタグ | 「最終更新:2026年3月」「カテゴリ:ネットワーク」。メタデータが検索精度を左右。詳細タグはAI自動付与でも可 |
| 6 | バージョン管理は履歴機能で | 「最終版_修正2_確定」を乱立させない。SharePoint等の履歴機能で最新版に限定 |
| 7 | AIがアクセスできる場所に置く | 個人PCやメール添付に埋もれさせない。クラウドストレージに置いて初めて検索対象に。置き場所も品質 |
AI Readyデータ:個人の習慣を組織の戦略へ
7つの習慣は個人の実践。組織として成功させるには、データを 「組織の資産」として戦略的に整備する視点が要ります。これを体系化したのが AI Readyデータ の概念です。Gartnerは「2026年までに、AI Readyデータの不備が原因でAIプロジェクトの60%が中止される」と予測しています。AIプロジェクトの成否は、AIの技術力ではなくデータの準備状況で決まる——この事実を経営層と共有できることが、ストラテジストの武器になります。
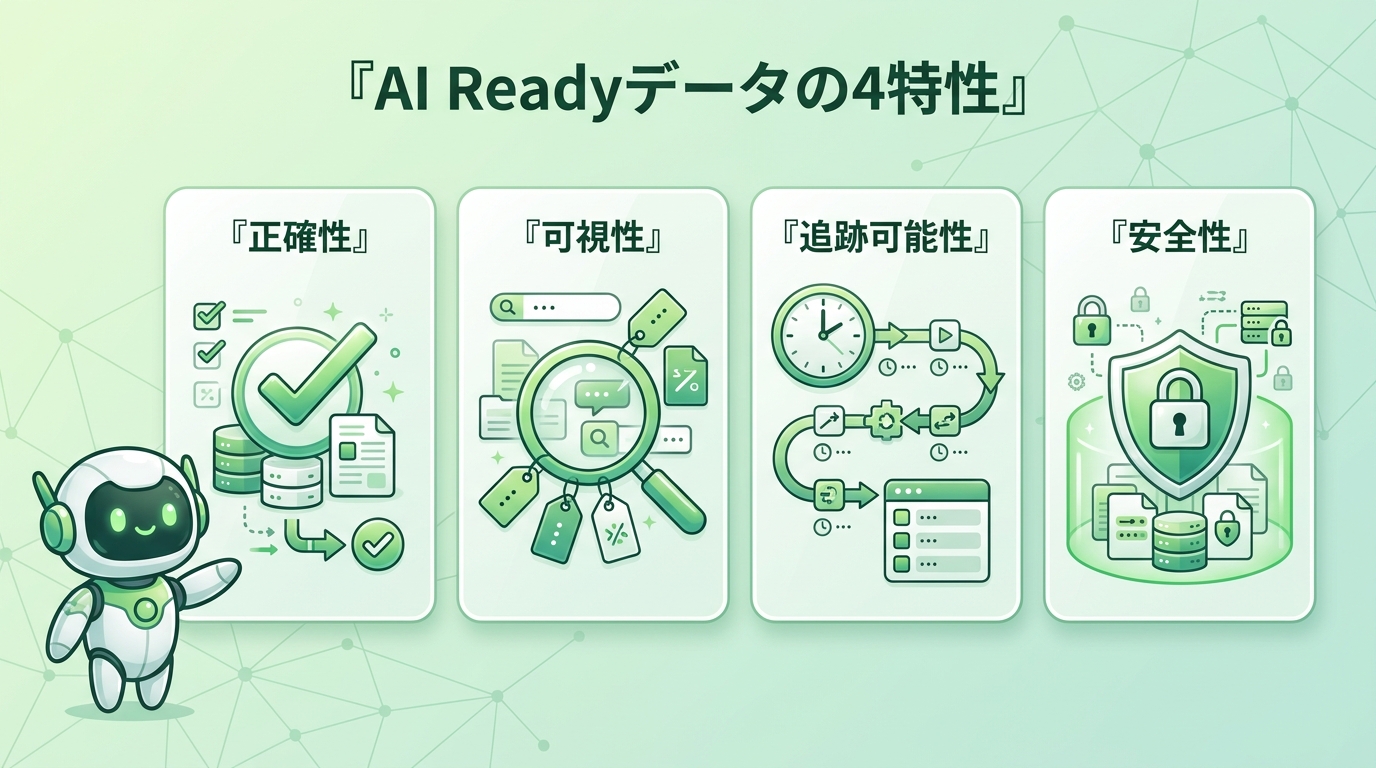
AI Readyデータとは AIが正確かつ安全に処理・活用できる状態に整備されたデータ。Gartnerは4特性で整理しています——正確性(矛盾がない)・可視性(所在と意味が明確、メタデータ整備)・追跡可能性(出所と変更履歴が追える)・安全性(アクセス制御とプライバシー保護)。7つの習慣のうち、習慣1〜4が正確性、習慣5が可視性、習慣6が追跡可能性、習慣7とガバナンスが安全性を支えます。個人の習慣は、組織のAI Readyデータ戦略の「実行の最前線」なのです。
ストラテジスト視点:既存データは「全部やる」が罠
「過去何年分ものデータをすべて整形すべきか」——答えは、まず利用対象となる範囲から優先的に整形すること。最初から全件を整備する必要はありません。BPRと同じく「全部やる」は着手を遅らせる罠です。そして、データ整備はAI導入の「準備」ではなく 導入そのものの一部。データを単なる記録ではなく、AIが活用する資産として設計する視点が、これからのストラテジストには求められます。
試験ではこう問われる(予想問題)
本試験は架空企業のケースをもとにした多肢選択式(4択)です。Section16の理解度を測る問題は、たとえば次のような形が予想されます。選択肢をクリックして解答してみてください(※当サイト独自の予想問題であり、公式の出題ではありません)。
過去数年分のExcelデータが大量に蓄積されている企業が、AIエージェント導入のためにデータ整備を始める。進め方として最も適切なものはどれか。
このセクションの要点まとめ
- 人の読みやすさ ≠ AIの読みやすさ。AIが扱いやすいのは「記述だけで意味が分かる/1項目1情報/構造が文字で明示」されたデータ。「AIが見えないものは存在しないのと同じ」。
- 7つの習慣:固有名詞で書く/構造で作る/入力をラクにする環境/画像に注釈/日付・カテゴリタグ/履歴機能でバージョン管理/AIがアクセスできる場所に置く。
- AI Readyデータの4特性=正確性・可視性・追跡可能性・安全性。Gartnerは2026年までにデータ不備でAIプロジェクトの6割が中止と予測。
- 成否はAIの技術力ではなくデータの準備状況で決まる。これを経営層と共有できることが武器。
- 既存データは「全部やる」が罠。利用対象範囲から優先。データ整備は導入の一部。
関連記事・次に読む
※本記事は、AICX協会 公式シラバスver1.0 の構成(Section16「AIエージェントが読みやすいデータを作る」)に基づき、当サイトが独自に解説・例示したものです。Gartner等の調査数値は各社の公表内容に基づく参考情報であり、最新の数値は各社の一次情報をご確認ください。公式テキスト本文・図版の転載は行っていません。図はすべて当サイトのオリジナルです。例示や予想問題は当サイトオリジナルであり、実際の出題内容を示すものではありません。最新の正式情報は AICX協会公式サイト をご確認ください。

