
本記事は、AIエージェント・ストラテジスト試験(AICX協会主催)の公式シラバスver1.0 Chapter 3 / Section 13「データの種類と特性」 の解説です。AIエージェントを設計するとき避けて通れないのが 「このデータは、誰が(何が)処理すべきか」 という問い。データの種類を見極め、最適な担い手を割り当てる発想が、設計の根幹になります。
到達目標は、構造化・非構造化・半構造化データの定義と具体例、メタデータの役割、各データの特性を理解すること。具体的な活用方法(RAG)は Section14 で扱います。
なぜデータの種類を区別するのか
売上データや顧客リストのような数値・項目の集合と、メール文面や議事録のような自然言語の文章では、適した処理方法が異なります。前者は従来のデータベースやシステムが得意、後者はLLMが真価を発揮する領域です。この区別がないまま設計すると、「LLMに向かない処理まで任せてコストを無駄にする」「従来システムでは扱えないデータを活かせず放置する」という判断ミスが起きます。
3種類のデータと、それぞれの担い手

| 種類 | 特徴・具体例 | 適した担い手 |
|---|---|---|
| 構造化データ | 行と列の明確な構造(DB・Excel)。受注履歴、社員情報、仕訳。検索・集計が容易 | API・定型処理 |
| 非構造化データ | 明確な構造なし(メール・チャット・Word・PDF・画像・音声・動画)。企業データの約8割 | LLM |
| 半構造化データ | タグ・キーで部分的に整理(名刺・JSON・XML)。中間的な存在 | AIの入出力インターフェース |
従来のITでは「メール文面から問い合わせの意図を理解する」のは困難でしたが、非構造化データの処理こそ生成AIの最大の強みであり、企業がAIエージェントを導入する動機の中核です。一方、構造化データの取得や集計は、わざわざLLMに頼らずAPI・定型処理に任せたほうが正確・高速・低コスト。半構造化(JSON)は、LLMの出力を構造化して後続システムへ渡すインターフェースとして実務で頻繁に登場します。
1つの業務フローに複数のデータが混在する
実務では、1つの業務フローに複数種類のデータが混在するのが普通です。だから設計上の重要な問いは「このデータは何種類あるか」ではなく、「業務フローのどの場面で、どの種類のデータが発生し、どの仕組みが処理するか」を整理することです。
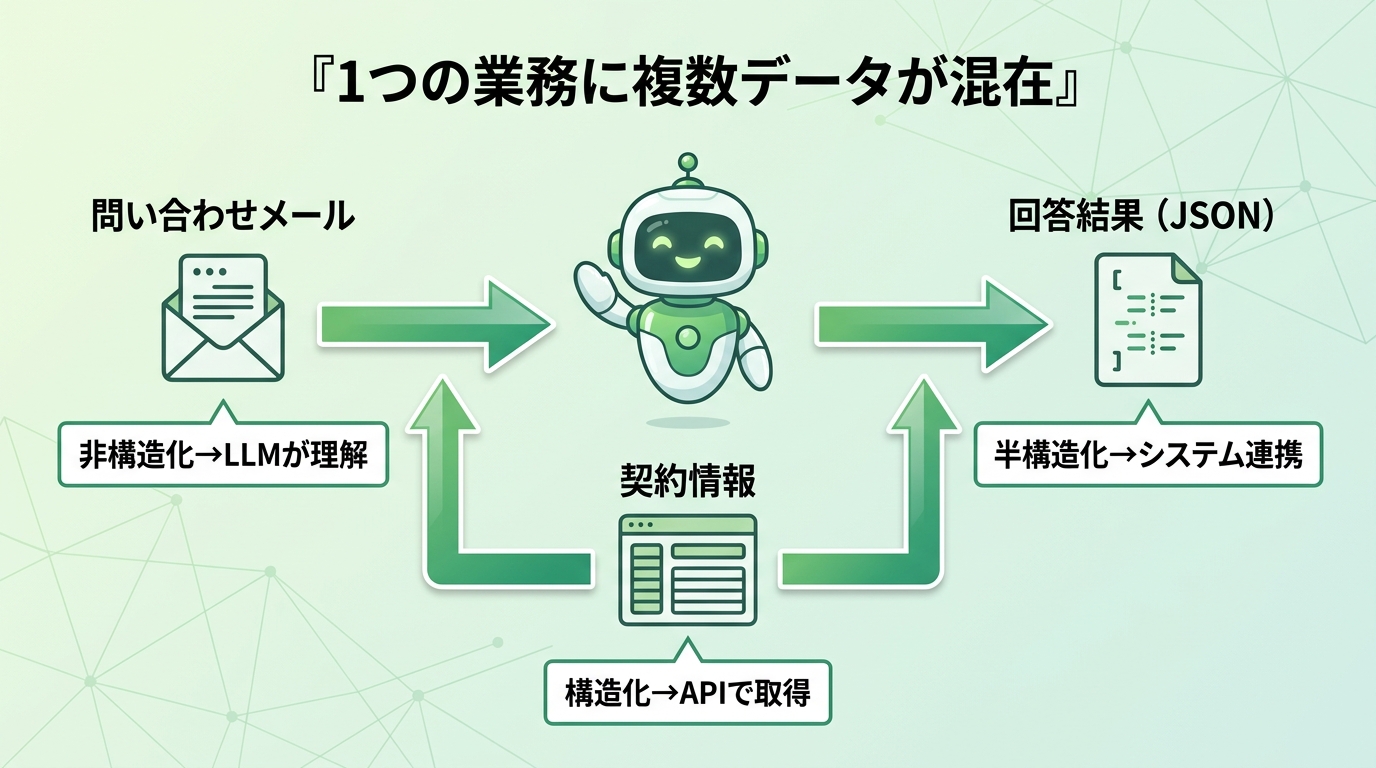
たとえば顧客対応AIなら、問い合わせメール(非構造化)はLLMが意図を理解し、顧客の契約情報(構造化)はAPIで取得し、回答結果(JSONの半構造化)はCRMへ連携する——という設計になります。重要なのは すべてをAIエージェントに任せない という前提。構造化の取得はAPIに、非構造化の理解はLLMに、それぞれの強みを組み合わせることで、精度・速度・コストのすべてが最適化されます。これは Section4(ハイパーオートメーション) の考え方ともつながります。
ストラテジスト視点:メタデータがデータの「文脈」を作る
メタデータとは「データについてのデータ」。ITマニュアル本文がデータなら、「カテゴリ:VPN」「対応OS:Windows 11」「最終更新日:2026年1月」がメタデータです。これが RAGの検索精度を左右 します。カテゴリタグが付いていればVPNの問い合わせに該当文書を素早く特定できますが、メタデータが未整備だと 正しい情報がナレッジベースにあってもAIが適切なタイミングで参照できない。ナレッジベースの品質は、コンテンツの質だけでなく メタデータの設計 でも大きく変わります。
そして、過去データをすべてさかのぼって整備するのは現実的でないことが多いもの。より大切なのは 「今後作成・更新するデータを、AIが読み取りやすい形で蓄積する運用」 を定着させることです(1セル1データ、表記統一、ファイル名に日付・分類、カテゴリ付与など——詳しくは Section16)。データ整備はAI導入の「準備」ではなく その一部。データを記録ではなく AIが活用する資産 として設計しましょう。
試験ではこう問われる(予想問題)
本試験は架空企業のケースをもとにした多肢選択式(4択)です。Section13の理解度を測る問題は、たとえば次のような形が予想されます。選択肢をクリックして解答してみてください(※当サイト独自の予想問題であり、公式の出題ではありません)。
顧客対応AIエージェントを設計している。データの種類と処理の担い手の組み合わせとして最も適切なものはどれか。
このセクションの要点まとめ
- データは3種類。構造化(DB・Excel)→API・定型処理、非構造化(メール・PDF・画像/企業データの約8割)→LLM、半構造化(JSON・名刺)→入出力インターフェース。
- 非構造化データの処理が生成AIの最大の強み。一方、構造化はAPIのほうが正確・高速・低コスト。
- 1業務に複数データが混在。すべてAIに任せず、種類ごとに最適な担い手を割り当てる。
- メタデータ(データについてのデータ)がRAGの検索精度を左右する。タグ・属性の設計はRAGと一体で考える。
- 過去の一括整備より、今後のデータをAIが読みやすい形で蓄積する運用が重要(→Section16)。
関連記事・次に読む
- Section12:ナレッジマネジメントの基礎(形式知とナレッジベース)
- Section4:RPAとAIエージェントの違い(定型処理とLLMの使い分け)
- シラバス完全マップ(全6章32セクション一覧)
※本記事は、AICX協会 公式シラバスver1.0 の構成(Section13「データの種類と特性」)に基づき、当サイトが独自に解説・例示したものです。公式テキスト本文・図版の転載は行っていません。図はすべて当サイトのオリジナルです。例示や予想問題は当サイトオリジナルであり、実際の出題内容を示すものではありません。最新の正式情報は AICX協会公式サイト をご確認ください。

