
本記事は、AIエージェント・ストラテジスト試験(AICX協会主催)の公式シラバスver1.0 Chapter 3 / Section 14「RAGの仕組み」 の解説です。AIエージェントに 社内固有の知識 を教える標準技術がRAG。Section12(ナレッジマネジメント)と Section13(データの種類)の知識が、ここで合流します。
到達目標は、RAGの2フェーズの流れ、チャンク分割の設計判断、意味の近さで検索する仕組みを理解すること。技術の詳細はアーキテクトの領域ですが、精度が低いとき「どこに原因があり得るか」を構造的に把握できることが、ストラテジストには求められます。
なぜRAGが必要なのか
LLMは膨大な知識を持ちますが、それは インターネット上の一般情報が中心。自社の業務マニュアル・社内規程・製品仕様・対応履歴といった組織固有の情報は学習データに含まれず、仕組みがなければAIは参照できません。これを解決するのが RAG(Retrieval-Augmented Generation:検索拡張生成)=「LLMが知らない情報を、必要なときに検索して与える」仕組みです。社内ナレッジベースをリアルタイム検索し、結果をプロンプトに組み込んで回答することで、汎用モデルが自社固有の文脈で機能します。ナレッジマネジメントとRAGは 表裏一体 の関係です。
RAGの2フェーズ:「保存」と「検索・生成」
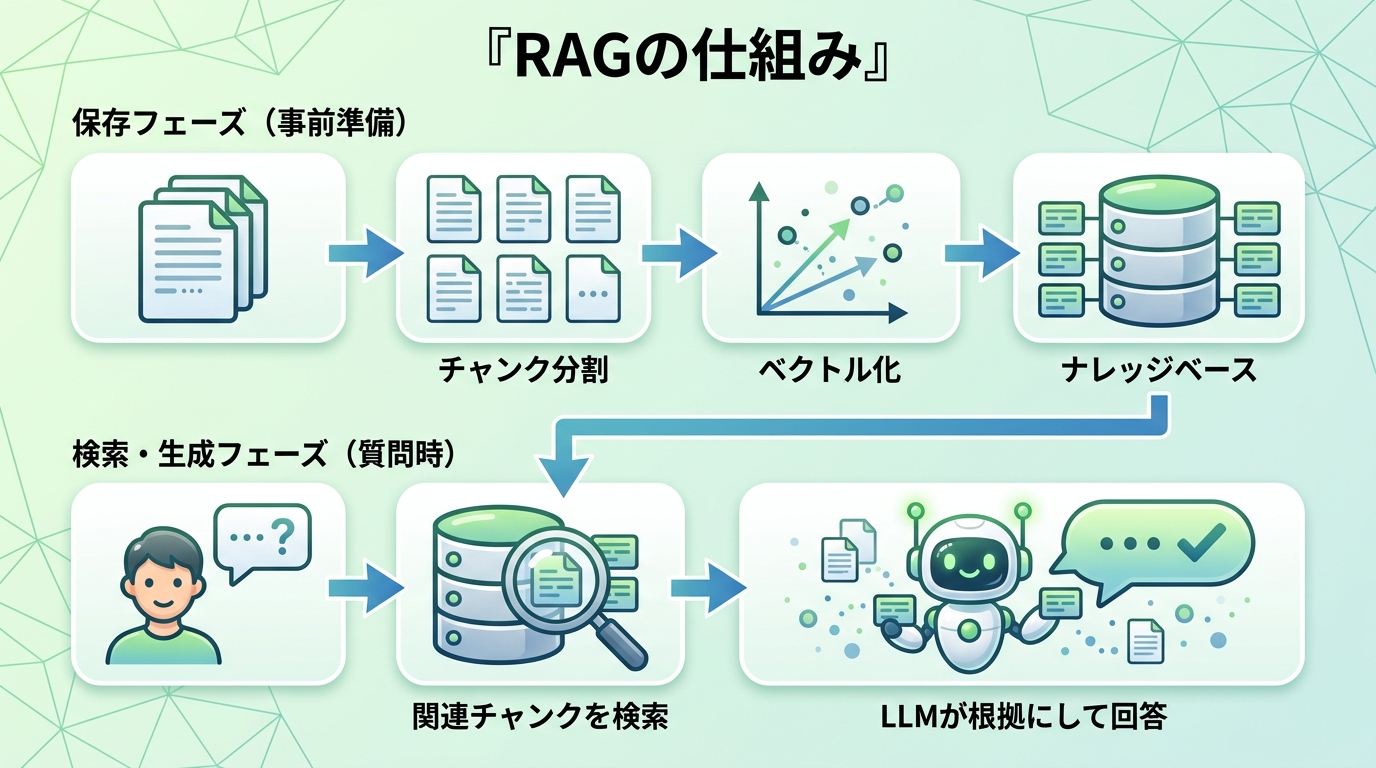
保存フェーズ:ナレッジベースを検索できる形にする
- チャンク分割:文書を適切なサイズの塊(チャンク)に分割。大きすぎると複数トピックが混ざりノイズに、小さすぎると文脈が失われる。目安は 「1トピック1チャンク」(マニュアルなら見出し単位)。
- ベクトル化:各チャンクを数値の列に変換。意味を数値で表現するので、「初期設定の手順を教えて」と「セットアップの方法は?」のように表現が違っても意味が近ければ近い数値になる。
- インデックス化:ベクトル化したチャンクをDBに格納し索引を作成。質問に対して瞬時に関連チャンクを照合できる状態にする。
検索・生成フェーズ:質問から回答へ
ユーザーの質問が来ると、まず質問をベクトル化し、ナレッジベースのチャンクと 意味の近さ で関連チャンクを検索します(キーワード完全一致ではない=セマンティック検索)。次に関連度の高い順に並べ替え、上位チャンクをLLMの入力に含め、LLMがそれを 根拠 として回答を生成します。このように回答を外部の文書に基づかせることを グラウンディング と呼び、根拠のない内容をもっともらしく答える(ハルシネーション)リスクを抑えます。
RAGの精度は「検索」と「生成」に切り分ける
RAGを入れただけでは不十分。「本当に正しい情報を検索できているか」「検索した情報をもとに正しく回答できているか」を評価する必要があります。RAGの精度は 検索の精度 と 生成の精度 の2段階で測ります。
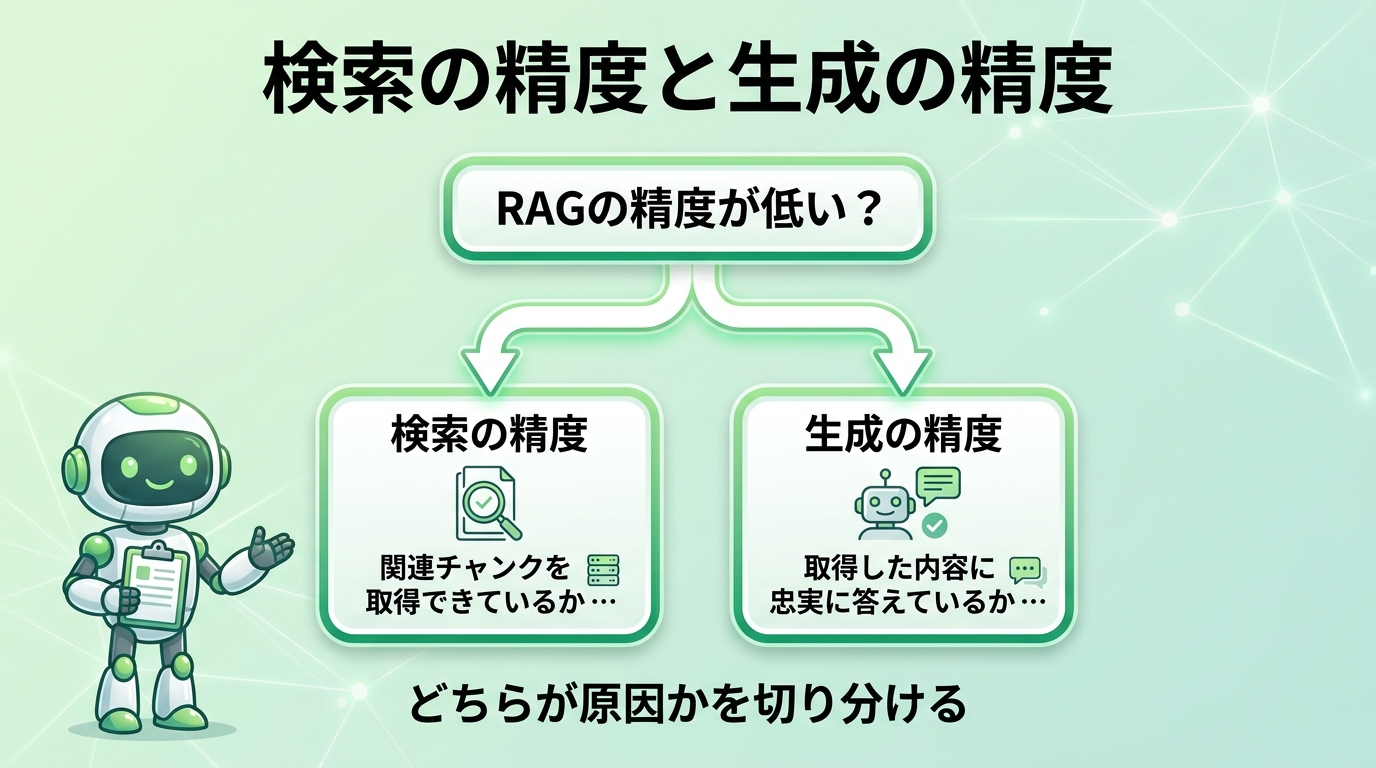
- 検索の精度:質問に関連するチャンクをどれだけ適切に取得できているか。検索が的外れなら、LLMがどれほど高性能でも正答できない。
- 生成の精度:取得したチャンクに忠実で、質問に過不足なく答えられているか。関連チャンクが取れても、LLMが内容を反映しなければ品質は出ない。
「RAGの精度が低い」という問題は、検索と生成のどちらに原因があるかを切り分けることが改善の出発点です。両者を区別しないまま対処すると、原因でない側を改善し続けることになります。
ストラテジストが押さえる4つの原則
- ① ナレッジベースの品質がRAGの精度を直接左右する。情報が不足・古い・整理不十分なら、どれほど高度なRAGでも適切な回答は得られない。
- ② チャンク設計は最初から完璧を目指さない。まず動くものを作り、テスト運用で問題を見つけて改善する。完璧を待ち続けるのが最悪。
- ③ メタデータの付与が検索精度を大きく左右する。カテゴリ・対応OS・更新日などのタグで、質問に合うチャンクを優先的に返せる(Section13)。
- ④ 精度問題は「検索」と「生成」に分けて原因を特定する。切り分けができないと、アーキテクトに的外れな改善指示を出し続けることになる。
検索精度を高める具体策(質問の変換・検索先の振り分け・リランキング/フィルタリング・チャンク設計とメタデータ)は段階的に。まず基本のRAGを運用し、具体的な問題が出た段階で、どの観点を改善すべきかをアーキテクトと議論する——その判断ができることがストラテジストの役割です。
試験ではこう問われる(予想問題)
本試験は架空企業のケースをもとにした多肢選択式(4択)です。Section14の理解度を測る問題は、たとえば次のような形が予想されます。選択肢をクリックして解答してみてください(※当サイト独自の予想問題であり、公式の出題ではありません)。
社内ヘルプデスクのRAGで「回答が的外れ」という問題が起きている。調査すると、ユーザーの質問に対して取得されているチャンクが質問とほとんど無関係なものばかりだった。まず改善すべき対象として最も適切なのはどれか。
このセクションの要点まとめ
- RAG=LLMが知らない自社情報を、必要なときに検索して与える仕組み。ナレッジマネジメントと表裏一体。
- 2フェーズ:保存(チャンク分割→ベクトル化→インデックス化)と検索・生成(セマンティック検索→グラウンディングで回答)。
- チャンクは「1トピック1チャンク」が目安。検索は表現でなく意味の近さで行う。
- 精度は検索の精度と生成の精度に分けて評価。「どちらが原因か」の切り分けが改善の出発点。
- ストラテジストの4原則:ナレッジベース品質・完璧を待たない・メタデータ・検索/生成の切り分け。
関連記事・次に読む
※本記事は、AICX協会 公式シラバスver1.0 の構成(Section14「RAGの仕組み」)に基づき、当サイトが独自に解説・例示したものです。公式テキスト本文・図版の転載は行っていません。図はすべて当サイトのオリジナルです。例示や予想問題は当サイトオリジナルであり、実際の出題内容を示すものではありません。最新の正式情報は AICX協会公式サイト をご確認ください。

